25. 01. 20 기록
Connection is read-only
[문제 상황]
게시글을 작성하려 하는데 아래와 같은 오류가 발생한다.
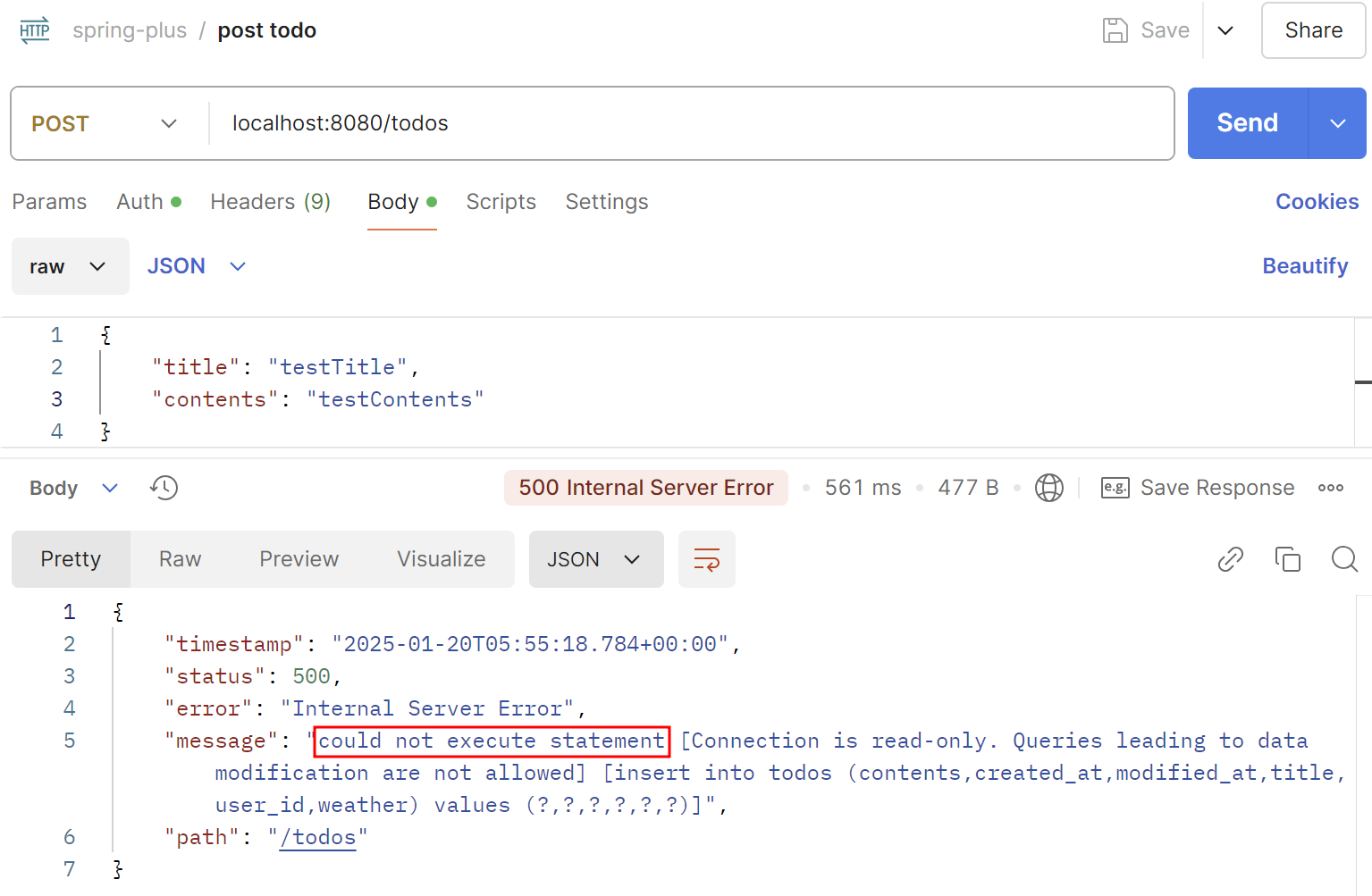
오류 전문은 다음과 같다.
jakarta.servlet.ServletException: Request processing failed: org.springframework.orm.jpa.JpaSystemException: could not execute statement [Connection is read-only. Queries leading to data modification are not allowed] [insert into todos (contents,created_at,modified_at,title,user_id,weather) values (?,?,?,?,?,?)] at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1022) ~[spring-webmvc-6.1.12.jar:6.1.12] at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:914) ~[spring-webmvc-6.1.12.jar:6.1.12]
스프링의 @Transactional 은 다음 두 가지 규칙이 있다.
1. 우선순위 규칙
클래스와 메서드 두 곳에 @Transactional이 적용되어 있을 경우,
더 가까운 곳에 있는 @Transactional이 적용된다.
2. 클래스에 적용하면 메서드는 자동 적용
클래스에만 @Transactional이 적용되어 있을 경우,
해당 클래스에 속한 메서드는 클래스에 적용된 @Transactional 속성을 적용 받는다.
따라서, TodoService 클래스에 적용한 트랜잭션 read-only 속성이 saveTodo()에도 적용되면서 발생한 오류로 추측할 수 있다.

[해결시도]
그렇다면 @Transactional 적용 여부를 어떻게 확인할 수 있을까? 🤔
필자는 AOP를 사용하여 직접 로그를 찍어보았다.
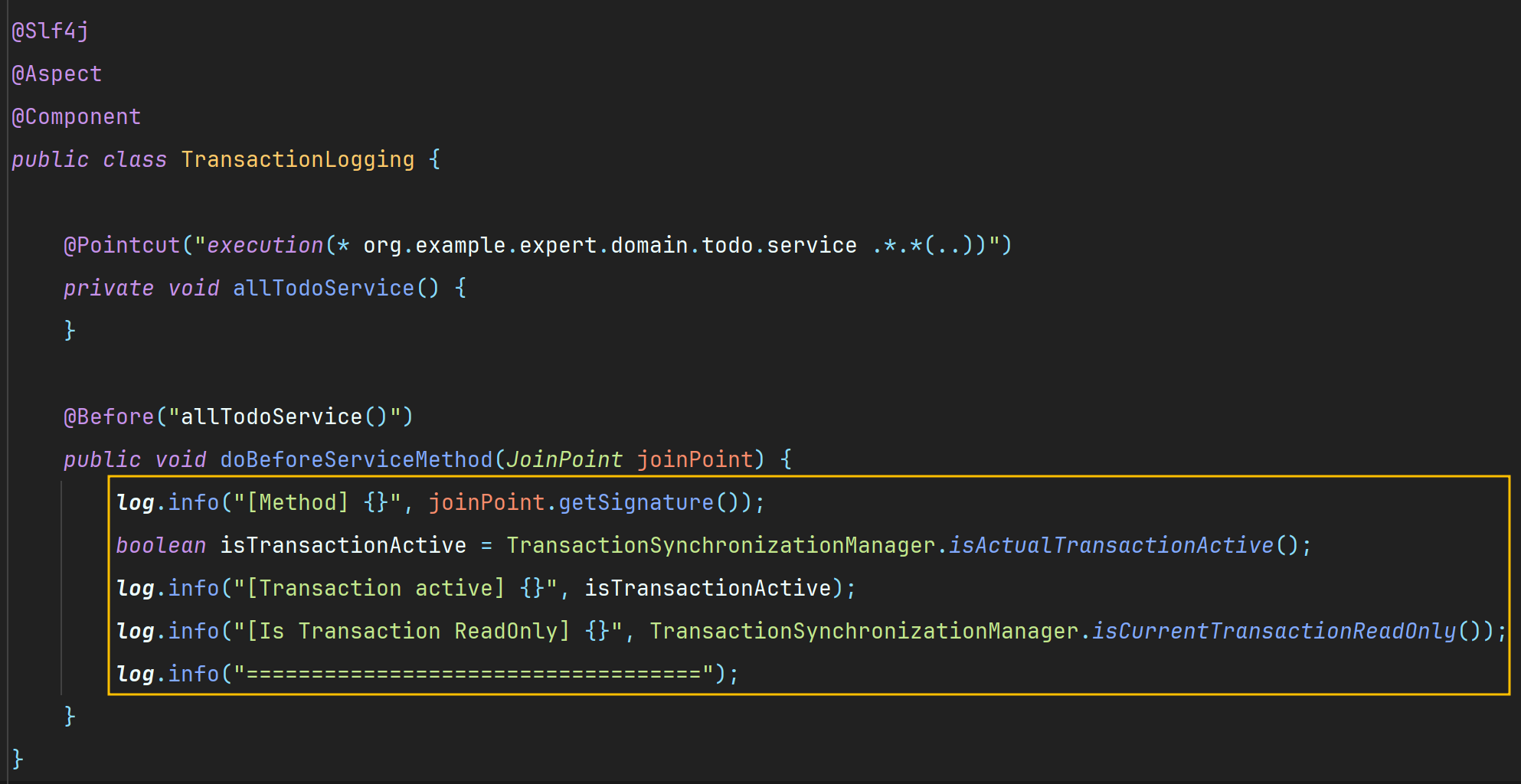
위 코드를 작성하기 전에 일단 application.properties에 아래 설정을 추가해준다.
logging.level.org.springframework.transaction.interceptor=TRACE이 설정을 추가하면 트랜잭션 프록시가 호출하는 트랜잭션의 시작과 종료를 명확하게 로그로 확인할 수 있다.
그리고 AOP에는 다음 두 가지 기능을 사용했다.
1. 현재 쓰레드에 트랜잭션이 적용되어 있는지 확인할 수 있는 기능
TransactionSynchronizationManager.isActualTransactionActive()결과가 true 면 트랜잭션이 적용되어 있는 것이다.
트랜잭션의 적용 여부를 가장 확실하게 확인할 수 있다.
2. 현재 트랜잭션에 적용된 readOnly 옵션의 값을 반환하는 기능
TransactionSynchronizationManager.isCurrentTransactionReadOnly()
포인트컷을 사용해서 TodoService 클래스에 AOP를 적용하고 saveTodo()를 실행해보면 아래와 같은 로그가 출력된다.

saveTodo()에 read-only 속성이 적용되어있고, 또 활성화 되어있는 것 까지 확인할 수 있다.
[해결]
saveTodo()에도 따로 @Transactional을 추가하여 read-only속성이 false가 되도록 하였다.
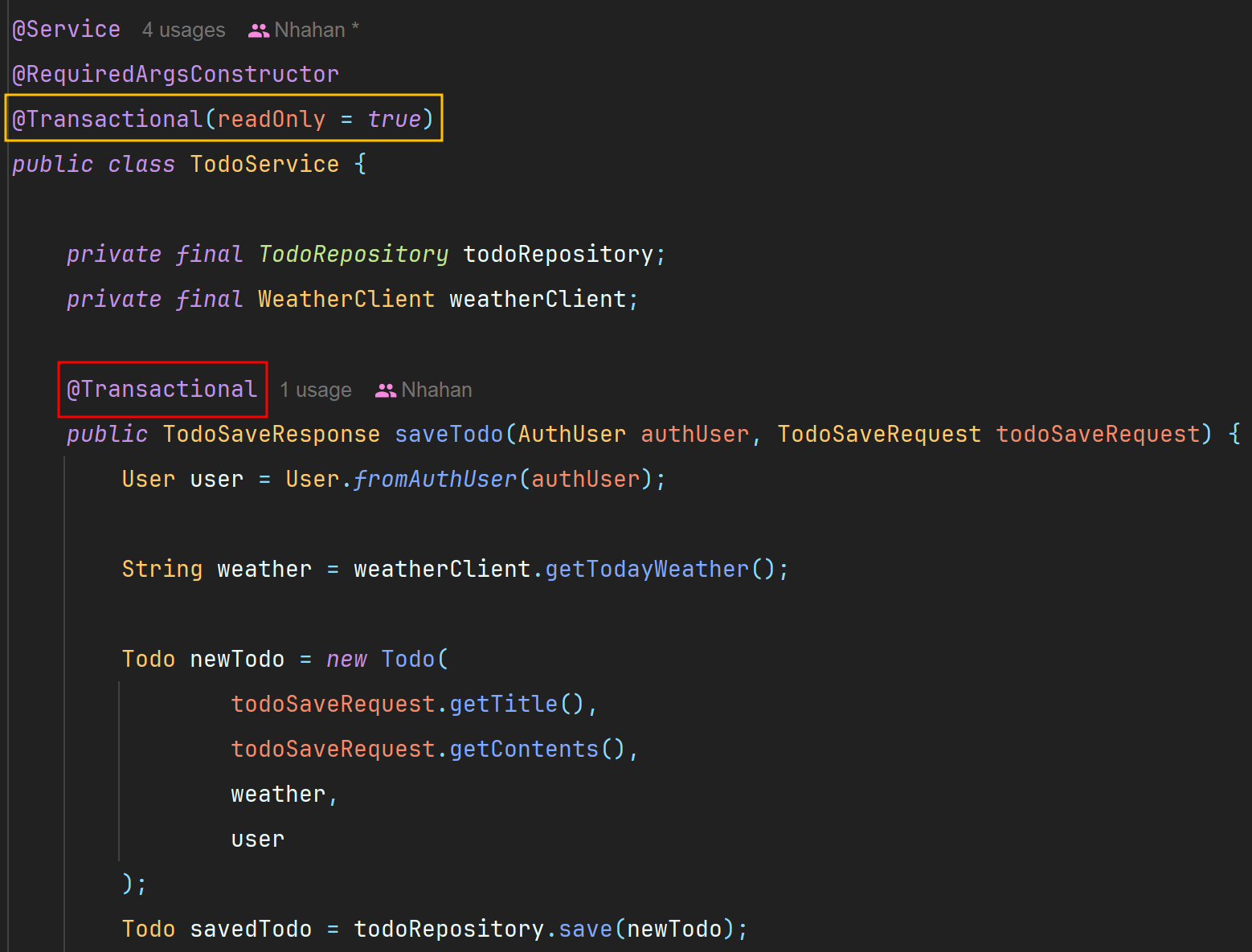
로그를 확인해보면 read-only속성이 false가 된 것을 확인할 수 있다.

글을 게시하는 기능도 정상적으로 동작한다.
25. 01. 21 기록
컨트롤러 테스트 코드 수정
[문제 상황]
todo_단건_조회_시_todo가_존재하지_않아_예외가_발생한다() 테스트가 실패하고 있다.


[해결 시도]
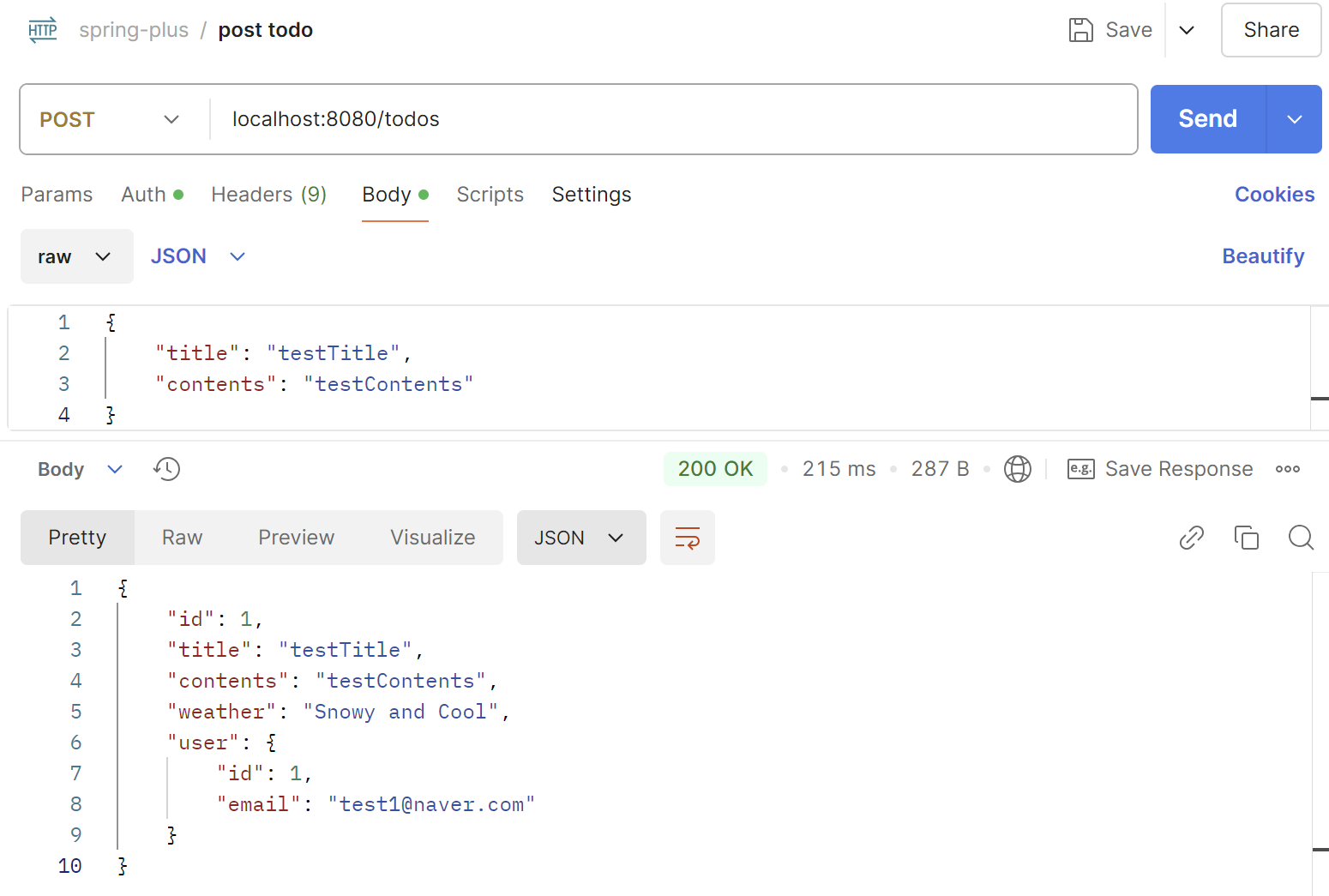
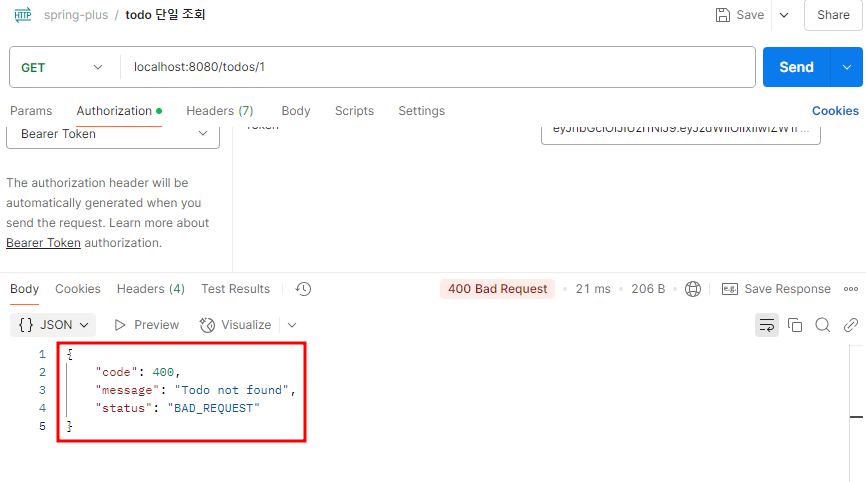
Todo 단건 조회를 postman으로 실행해보았다.
이때 의도적으로 아무런 일정도 조회되지 않도록 해보면 다음과 같이 BAD_REQUEST 상태가 반환된다.
좀 더 디테일하게 코드를 살펴보자.
먼저 Todo 단건 조회 메서드인 getTodo()를 살펴보았다.
조회되는 일정이 없을 경우 InvalidRequestException을 반환하는 것을 확인할 수 있다.

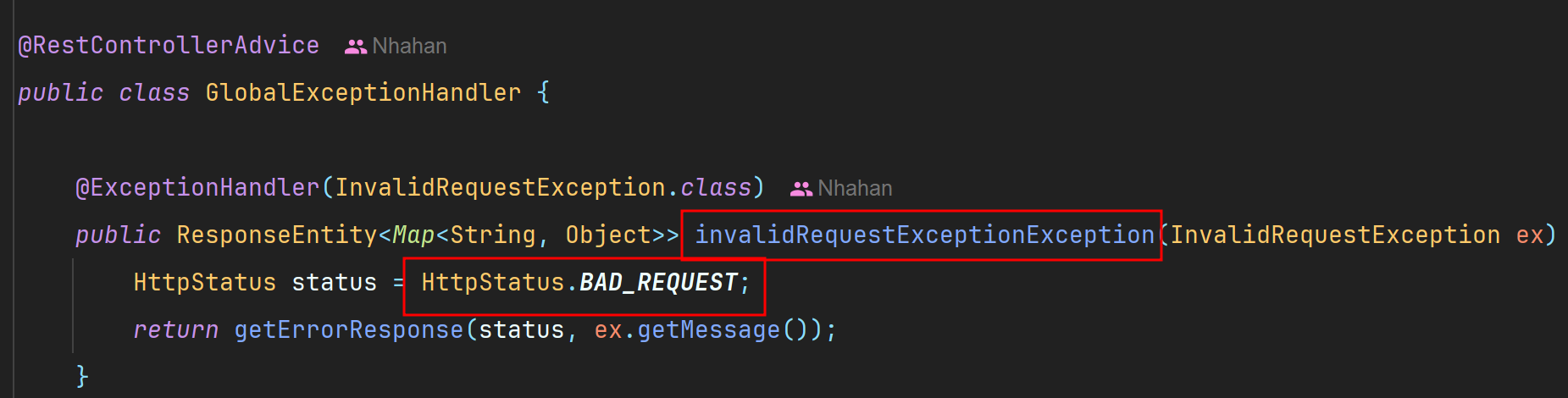
다음으로 InvalidRequestException이 어떻게 커스텀되어 사용되고 있는지 알기 위해 GlobalExceptionHandler를 살펴보았다.
InvalidRequestException은HttpSatus.BAD_REQUEST를 반환하도록 되어있다.
[해결]
다시 테스트 코드를 살펴보면 HttpStatus 값으로 BAD_REQUEST가 아닌 OK로 설정되어 있는 것이 테스트코드의 실패 원인임을 알 수 있다.
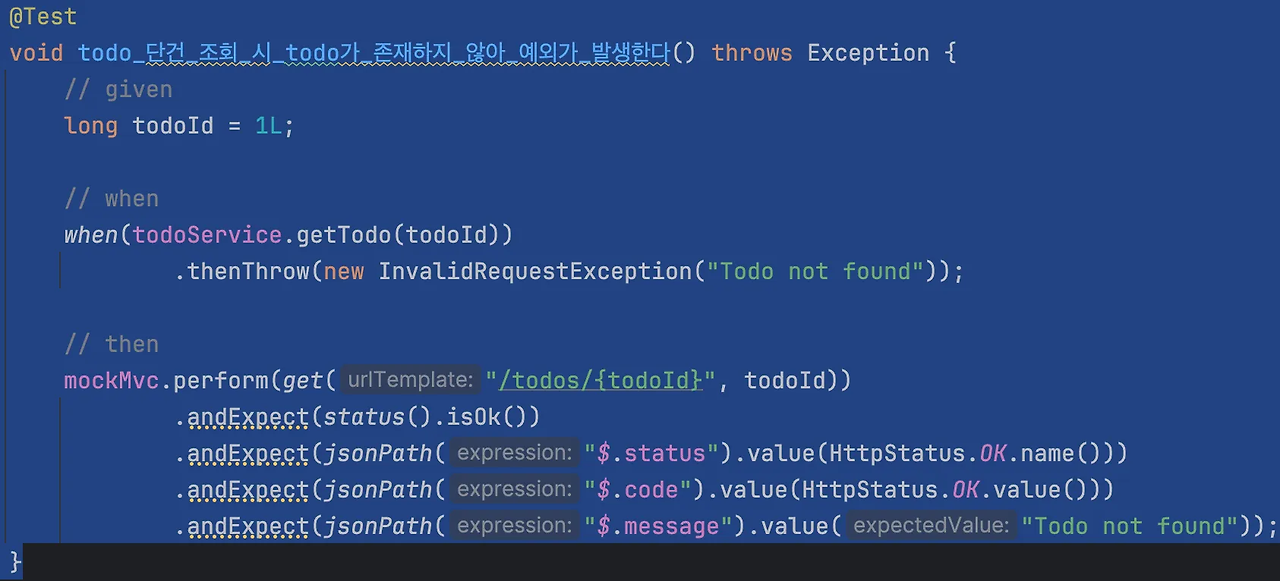
따라서 응답 값을 다음과 같이 모두 BAD_REQUEST로 수정하였다.

25. 01. 24 기록
서브쿼리를 join으로 단순화 해보자 (feat. QueryDSL)
[문제 상황]
QueryDSL을 사용한 검색 기능을 만들었다.
검색 조건과 결과는 다음과 같다.
1. 제목으로 검색. 제목은 부분적으로 일치해도 됨.
2. 생성일 범위로 검색. 생성일 기준 최신순으로 정렬.
3. 담당자 닉네임로 검색. 닉네임은 부분적으로 일치해도 됨.
1. 일정 제목
2. 해당 일정의 담당자 수
3. 해당 일정의 총 댓글 개수
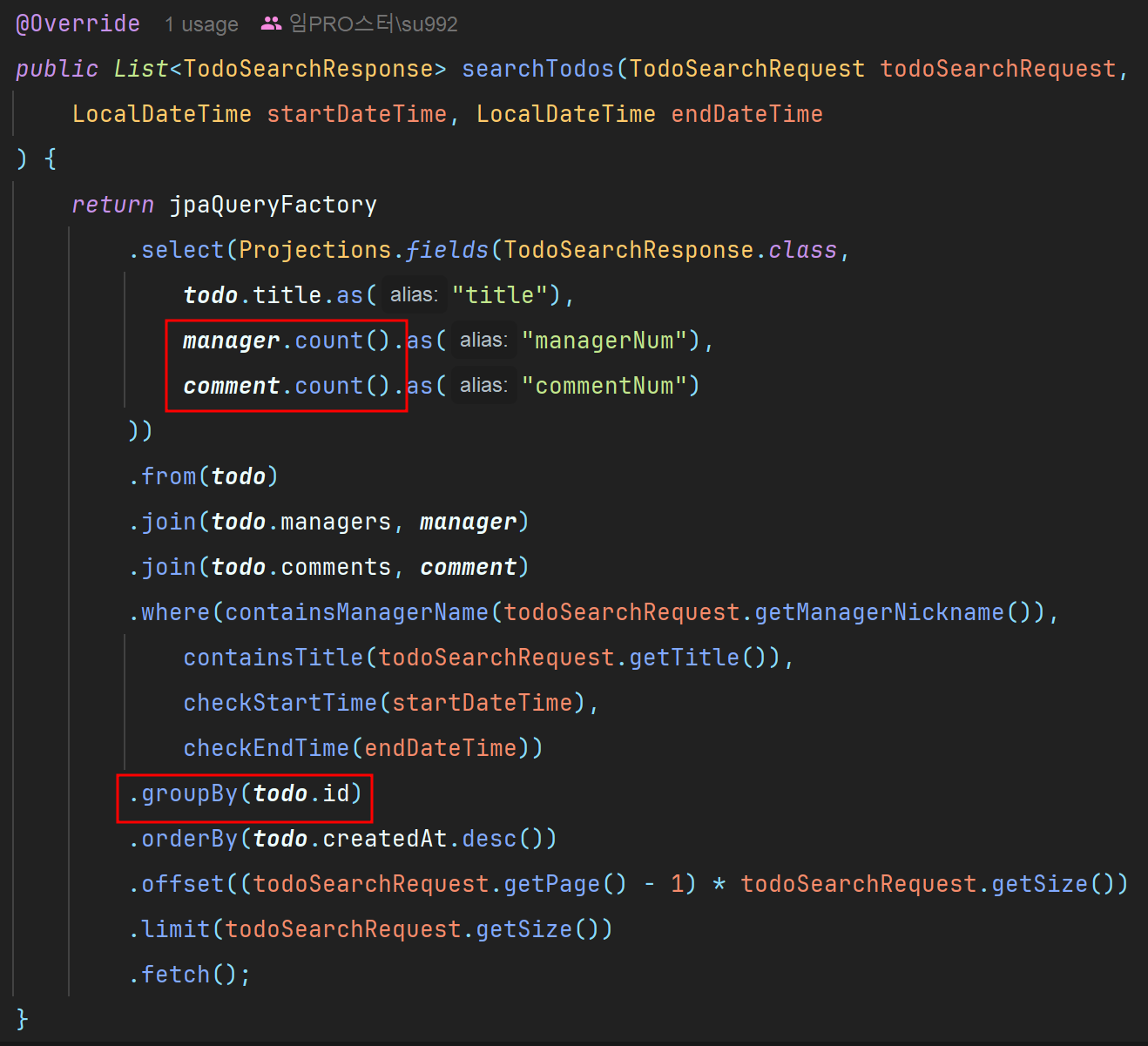
해당 검색 기능을 구현하면서 위의 검색 결과 박스에서 빨간색으로 표시해둔 부분이 정말 어려웠다.
개수를 어떻게 반환해야할지 도무지 감히 잡히지 않았는데, 아래는 제일 처음 구현했을 때의 코드이다.
서브쿼리를 사용해서 어떻게든 개수를 구해보려고한 흔적...
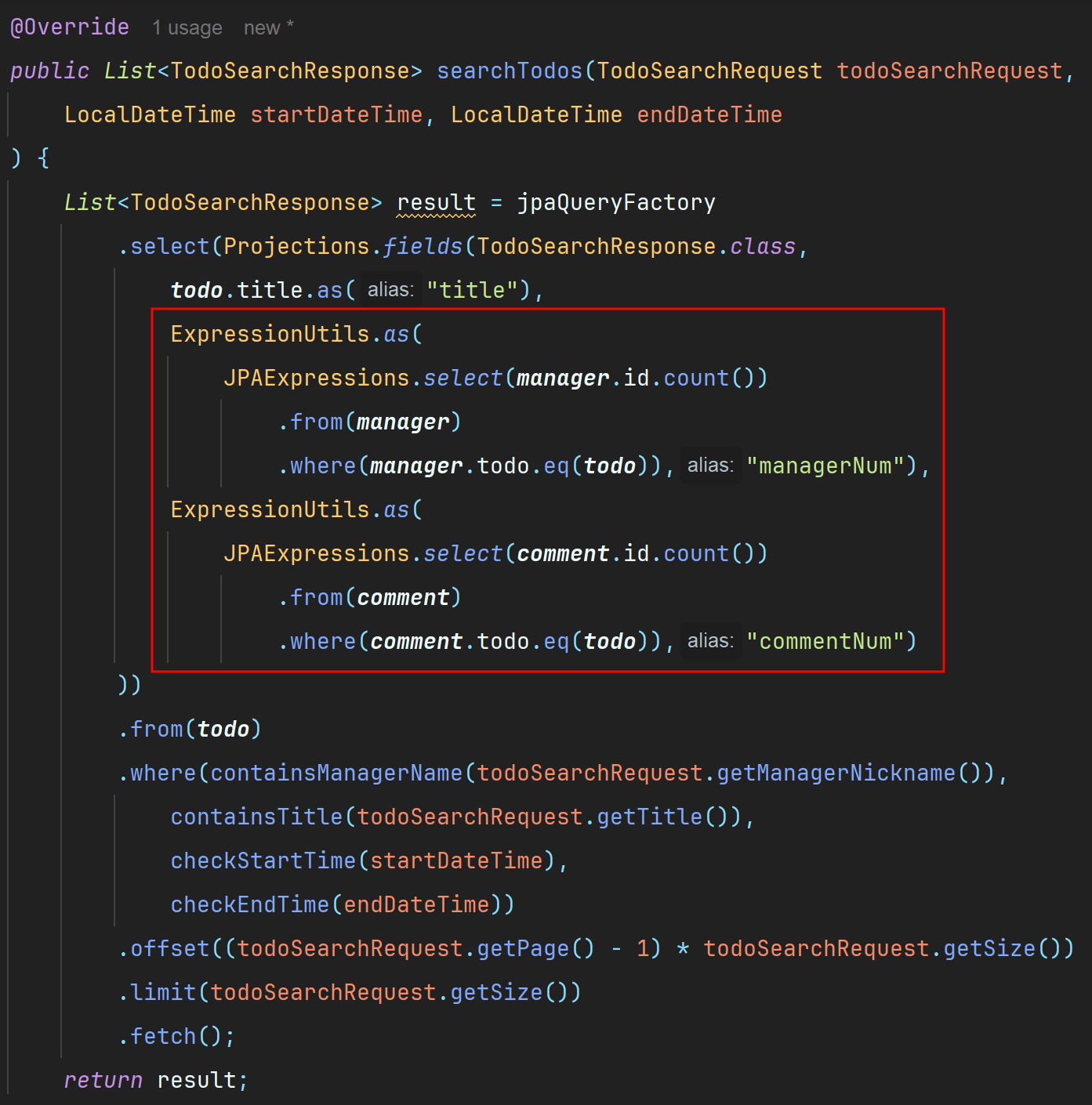
하지만!!
서브쿼리는 효율이 떨어진다는 정보와 함께 해당 검색 기능은 join으로도 충분히 구현 가능하다는 피드백을 받았다.
[해결 시도]
먼저 현재 상태를 정리해보았다.
'manager, comment 테이블을 서브쿼리로 각각 조회하고 있음'
그러다보니 이런 의문점이 들었다.
' manager, comment 테이블은 todo 테이블과 연관 관계에 있으니까 join해서 불러올 수 있지 않을까? '
그래서 아래와 같이 코드를 수정해보았다.

' join도 했고 서브쿼리도 없앴으니까 이제 괜찮겠지?😊 '
라고 생각했던 것도 잠시.. SQL문이 어떻게 나가는지 살펴보았더니 여전히 서브쿼리가 나간다.. 🥹
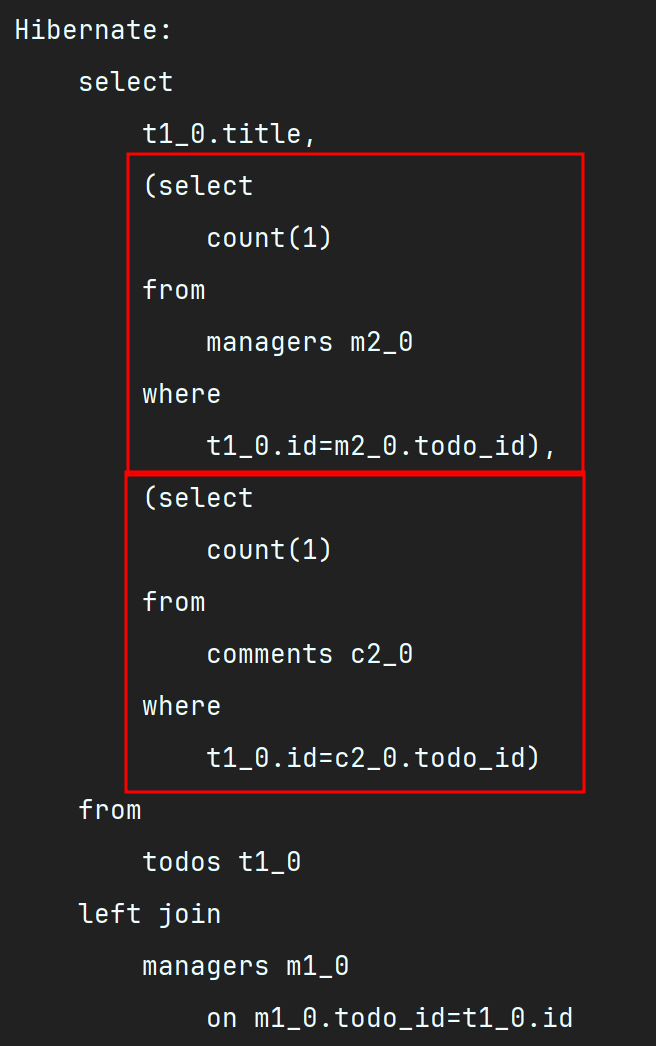
왜 그럴까?
찾아본 바에 의하면 todo.managers.size()와 todo.comments.size()를 사용하면 Hibernate가 이를 처리하기 위해 내부적으로 서브쿼리를 생성하기 때문이다.
좀 더 구체적으로 설명하자면,
todo.managers.size()는 todo 엔티티와 연결된 managers 컬렉션의 크기를 반환한다.
하지만 JPA는 컬렉션 데이터를 직접 SQL의 열(column)로 변환할 수 없다!
따라서 Hibernate는 해당 컬렉션에 대해 SQL을 따로 생성해 개수를 별도로 계산해야 한다.
한줄 요약:
.size() 쓰면 서브쿼리가 만들어진다.
[해결]
그러면 어떻게 해야할까?
답은 이미 서브쿼리에도 나와있다. count()를 사용하면 된다.
이렇게 하면 서브쿼리 없이 매핑된 테이블을 카운트할 수 있다.

실행 결과를 보면 SQL문에 서브쿼리 없이 count()만 깔끔하게 나간 것을 확인할 수 있다.
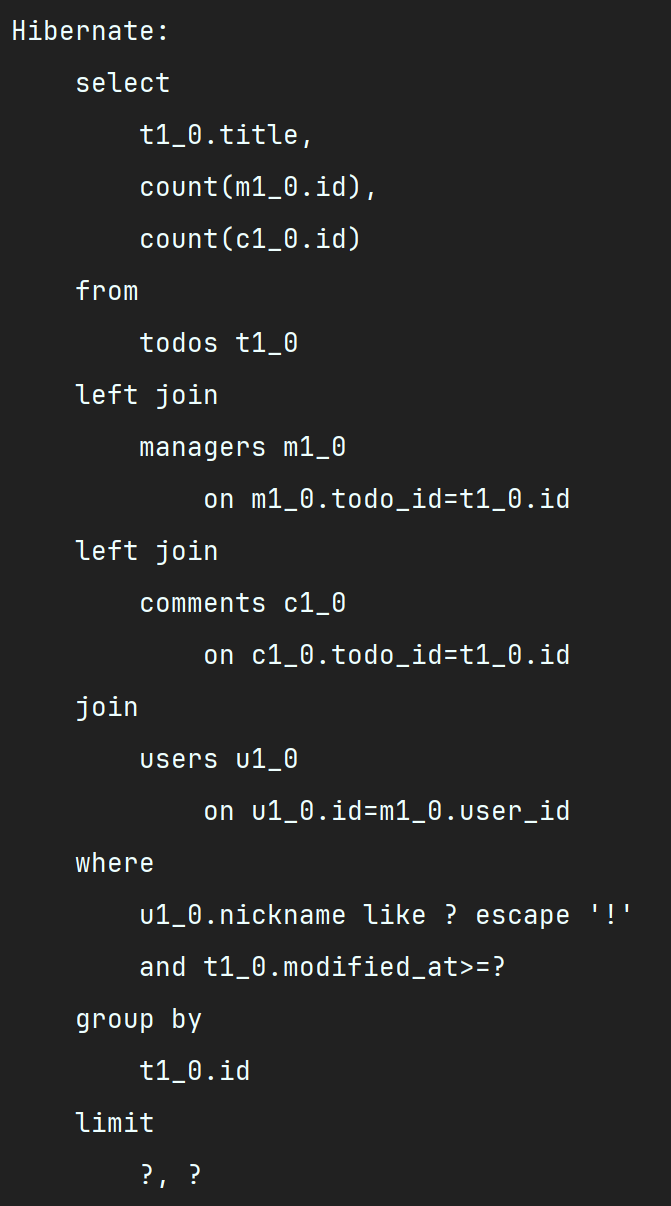
25. 01. 24 기록
카테시안 곱(Cartesian Product) 문제
[문제 상황]
일정 검색시 조회 결과가 댓글 개수만큼 중복해서 출력되는 문제가 있었다.

[해결 시도]
위에서 사용했던 코드를 다시 들고왔다.
실행시켜보면 todo 테이블에 3개의 테이블이 inner join으로 연결되어있음을 확인할 수 있다.

todo는 1개
tood_id =1
tood_id =1에 대한 매니저 1명
tood_id =1에 대한 댓글 6개
라고 했을 때 manger 와 comment, user 그리고 todo 를 join한 테이블을 그려보면 다음과 같다.
댓글 개수에 따라서 중복되는 데이터가 늘어나는 것을 확인할 수 있다.
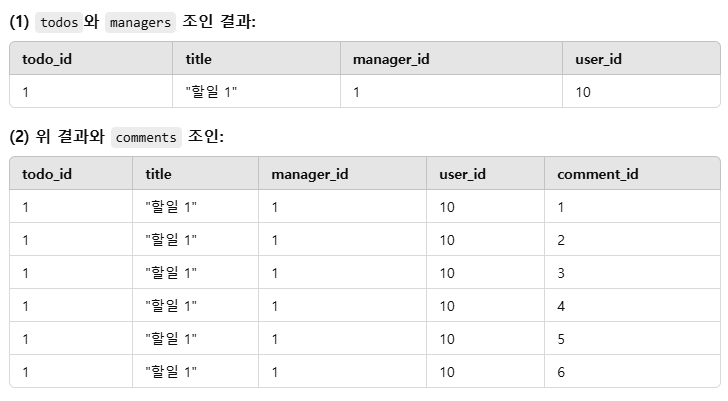
따라서 중복 처리를 해주지 않으면 같은 일정이 댓글 개수만큼 중복해서 출력될 수 밖에 없다.
즉, 카티시안 곱 현상이 발생하는 것..
(todo 테이블과 다른 테이블들이 OneToMany 관계라서 이런 일이 생긴 것 같다.)
[해결]
groupBy()를 사용해서 중복된 결과가 나타나지 않도록 조치 했다.
groupBy()를 사용할 경우 각 그룹에서 어떤 데이터를 반환할지 명시해야하기 때문에 집계함수를 꼭 사용해야한다.
서브쿼리를 없애기 위해서라도, groupBy()를 위해서라도.. count() 사용은 꼭 필요했다.